Optimalizace je velmi důležité téma a optimalizace v datovém skladu může být občas trochu odlišná od optimalizace v OLTP systémech. Důležité je zmínit exekuční plán, statistiky, způsoby joinování, materializaci, indexy a partitioning. Toto je jedna z náročnějších kapitol na čtení a je poměrně obsáhlá – hodí se mít vhled do teorie grafů. Exekuční plán Když vytvořím databázový dotaz. Existuje k němu několik exekučních plánů. Databáze je vytvoří na pozadí a vybere z nich ten, o kterém si myslí, že je nejlepší (A né vždy si to myslí správně a je jí potřeba popostrčením navést ke správnému řešení). Každý plán má určitou cenu, kterou databáze vypočte na základě statistik, které si…
-
-
Tipy & Triky – 12. díl
Tentokrát projdu moje tipy a triky, které by se mohly někomu hodit. Jde o spíš o maličkosti, které ulehčují práci. Rychlá záloha tabulky Prvním tipem je rychlá záloha tabulky. /* Zazálohování tabulky do schématu bck*/ SELECT * INTO bck.BACKUP_DIM_CALENDAR_20231124 FROM l2.DIM_CALENDAR; SELECT * FROM bck.BACKUP_DIM_CALENDAR_20231124/* Zazálohování tabulky do schématu bck*/ SELECT * INTO bck.BACKUP_DIM_CALENDAR_20231124 FROM l2.DIM_CALENDAR; SELECT * FROM bck.BACKUP_DIM_CALENDAR_20231124 Kontrola že jsem nic nepokazil Když dělám, nějakou změnu a ovlivní jen určitou část tabulky. Kontroluji si, že jsem nezměnil počet řádků a sedí na sebe hodnoty. Ukážu to na tabulce vytvořené v minulém kroku. /* Kontrola na počet záznamů */ SELECT COUNT(1) AS CNT FROM l2.DIM_CALENDAR; SELECT…
-
Surrogate keys v DWH – 11. díl
V tomto článku se zabývám konceptem surrogate keys v datovém skladu. Definici, výhody oproti přirozeným klíčům a metody generování. Surrogate key je unikátní identifikátor záznamu (id). Je uměle generovaný a nemá žádný vztah k obsahu. Oproti tomu přirozený (složený) klíč má vazbu na existující data. Na generovávání surrogate key existují různé techniky jako auto inkrement, sekvence, UUID, hash, a pod. Generování surrogate key Auto-Increment,Identity Většina databází umožňuje generování pomocí auto-incrementu nebo identity automaticky. Na pozadí bude většinou použita sekvence. V Postgres lze použít GENERATED AS IDENTITY. CREATE TABLE SURROGATE_KEY_AUTO ( ID INT GENERATED ALWAYS AS IDENTITY, VAL VARCHAR(10) );CREATE TABLE SURROGATE_KEY_AUTO ( ID int GENERATED ALWAYS AS IDENTITY, VAL varchar(10)…
-
Pokročilé agregační funkce – 10. díl
V nadcházejícím článku se zaměřím na windowed funkce. Ty provádějí pokročilé agregace nad specifickým "oknem" řádků, což rozšiřuje možnosti analýz. Věnuji si funkcím ROW_NUMBER, RANK, LEAD, LAG, FIRST_VALUE a dalším. Ukážu konkrétní příklady využití.
-
Orchestrace (noční load) – 9. díl
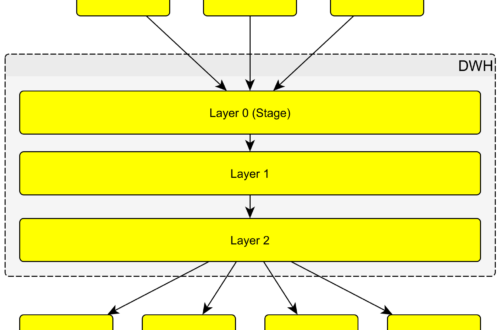
Orchestrace – co to je, jak vypadá, paralelizace jobů, příklady. Nástroje umožňující orchestraci (Jenkins, Data Factory, …). Orchestrace Orchestrace je uspořádání načítání jednotlivých tabulek do DWH a uvnitř DWH, případně i z DWH ven. Tato operace se většinou děje v noci nebo brzo ráno, protože je časově náročná. Typicky jsou loady jednotlivých tabulek shlukovány do jobů dle návaznosti nápočtu. Jednotlivé joby jsou pak spouštěny orchestračním nástrojem jako je například Jenkins. Na předchozím obrázku jsem znázornil větší detail datového skladu ve vrstvách. Orchestrace takového datového skladu by mohla vypadat následujícím způsobem. Jednotlivé joby loadující data z externích aplikací jako CRM, ERP jsou spouštěny zároveň (nijak se neovlivňují lze paralelizovat). Po jejich…
-
Pojmenovávání a dokumentace – 8. díl
Půjde o pojmenovávání a dokumentaci. Je extrémně důležité vést k celému projektu dokumentaci, správně pojmenovávat a dobře komunikovat. Ne vždy se tato aktivita setkává s pochopením, ale je nesmírně důležitá. Lidé si na to časem zvyknou a ve finále je daleko lepší provoz, někdy dokonce i levnější. Jak už komentovat kód, tak stejným stylem pojmenovávat objekty, používat jednotný code style. Uvedu tu několik dobrých principů, kterých se držet, aby Vám práce šla lépe.
-
Fakta v datovém skladu (DWH) – 7. díl
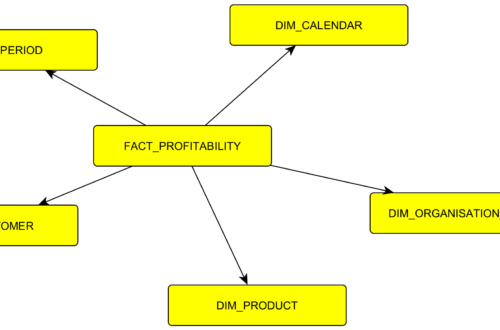
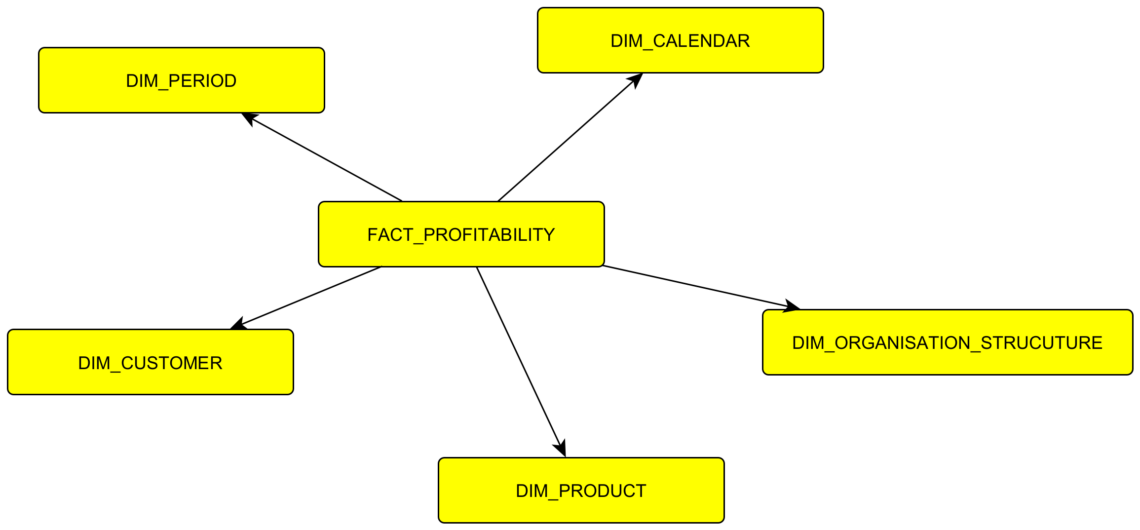
V tomto článku se věnuji faktovým tabulkám. Ukážu příklad na fakturách, dále se věnuji propojení faktových tabulek s dimenzemi, zmíním se o periodě loadu. K článku přikládám v odkazech i link na příklady v SQL, které si můžete při čtení zkoušet.
-
Dimenze v datovém skladu (DWH) – 6. díl
V tomto článku se podívám podrobněji na dimenze, jejich typy - STAR/SNOWFLAKE/CONSTELLATION, jejich plnění, úrovně historizace a typické dimenze v datovém skladu.
-
SQL funkce a DML – 5. díl
Rychle prolétnu zajímavé funkce, příkazy z SQL a zbylé DML operace INSERT, UPDATE, DELETE a MERGE. Pokud se na to cítíte můžete určitě článek přeskočit. V příštím už se konečně dostaneme k věcem bližším DWH.
-
SELECT – 4. díl
Tentokrát se věnuji klauzuli SELECT, a jejím příkazům, podrobněji se podívám na JOINy a jejich typy. Jelikož SELECT a JOINy jsou pro DWH stěžějní je potřeba se u nich pozastavit.