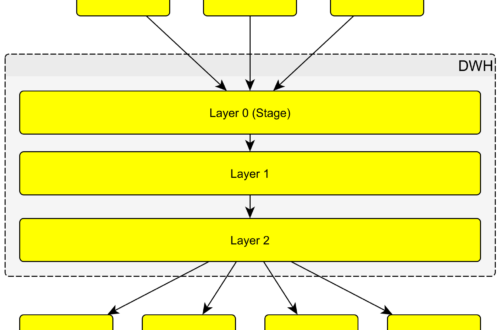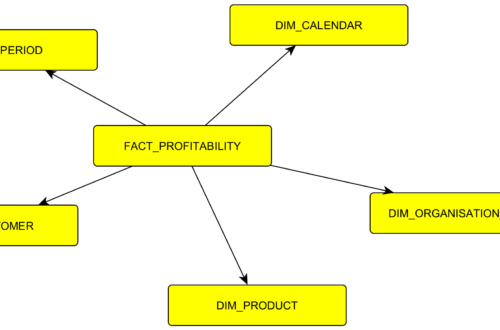
Zde se podrobněji věnuji vrstvám datového skladu. Jejich rozdělení, použití, externím tabulkám, výpočtům, přenosem mezi vrstvami, a také dimenzím a faktům. K článku přikládám jednoduchý soubor s příklady pro vytvoření databáze v PostgreSQL a schémat jako jednotlivých vrstev. DWH je rozdělen na vrstvy. Vrstvy l0, l1, l2 v DWH je jen označení, aby bylo zřejmé v jakém směru data plynou (l0 -> l1 -> l2). Samotné vrstvy pak reprezentuje schéma databáze. Když navrhuji tabulky v DWH, musím myslet na to, že pracuji s historickými daty. Kdykoliv udělám v průběhu vývoje změnu je třeba přepočíst všechny vrstvy, co se změnou souvisí i za všechna časová období. Jednodušeji řečeno – je možné celou tabulku smazat (platí pro…
-
-
Základní tipy v datovém skladu (DWH) – 2. díl
V tomto článku se podívám na dobré návyky v datovém skladu a základní tipy co Vám zlepší život, co se týče datových typů, transakčních dat vs. master dat a datumů.
-
Co je to datový sklad (DWH)? – 1. díl
Tento článek i následující články píši na témata o DWH (= DataWareHouse), BI (= Business Intelligence) a SQL (= Structured Query Language). Věnuji se datovému skladu, jeho vrstvám a rozdílu oproti relační databázi. Na internetu lze najít různé materiály o klasických relačních databázích, ale chyběl mi nějaký ucelený návod o datovém skladu, a proto jsem ho vytvořil. Než se do čtení pustíte, je dobré znát co je to relační databáze a SQL.