Orchestrace – co to je, jak vypadá, paralelizace jobů, příklady. Nástroje umožňující orchestraci (Jenkins, Data Factory, …).
Orchestrace
Orchestrace je uspořádání načítání jednotlivých tabulek do DWH a uvnitř DWH, případně i z DWH ven. Tato operace se většinou děje v noci nebo brzo ráno, protože je časově náročná. Typicky jsou loady jednotlivých tabulek shlukovány do jobů dle návaznosti nápočtu. Jednotlivé joby jsou pak spouštěny orchestračním nástrojem jako je například Jenkins.

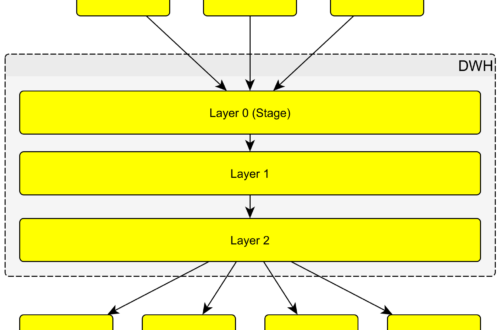
Na předchozím obrázku jsem znázornil větší detail datového skladu ve vrstvách. Orchestrace takového datového skladu by mohla vypadat následujícím způsobem. Jednotlivé joby loadující data z externích aplikací jako CRM, ERP jsou spouštěny zároveň (nijak se neovlivňují lze paralelizovat). Po jejich nápočtu se spustí joby pro nápočet dimenzí a dalších vrstev datového skladu a také materializace.

Jistě jste si všimli, že se jednotlivé joby mohou spouštět v jiný čas. To je vidět na jobu 25 DSR. Který by se mohl počítat velmi brzo, ale musí počkat na data z jiného systému, která posílá data až v 6:30. Job 12 tak představuje bariéru. Někdy není třeba mít bariéry takto explicitně a nástroje si se závislostmi na více než jednom předchůdci poradí samy – některé ovšem ne a je tak tuto problematiku mít na paměti.
Toto je jen jeden z možný scénářů nápočtu. V praxi mohou vypadat odlišně a pravděpodobně budou daleko více komplexnější. Orchestraci je potřeba mít pevně v rukou a tedy mít ji dobře zadokumentovanou. Hlavní část nočního loadu může trvat i několik hodin. I z tohoto důvodu se transakční data počítají jen za určité období.
Nástroje
Existuje nepřeberné množství nástrojů pro orchestraci. Osobně používám Jenkins, ale vybral jsem do následujícího seznamu i další zajímavé nástroje.
- Jenkins (jenkins.io)
- Open-source automatizace na serveru. Používaný pro sledování opakovaných úloh v procesu vývoje softwaru. Podporuje automatizaci sestavování, testování a nasazování aplikací.
- Microsoft Azure Data Factory (azure.microsoft.com/en-us/products/data-factory/)
- Služba v cloudu od Microsoftu, která umožňuje orchestraci a automatizaci přenosu dat mezi různými datovými úložišti a transformaci dat v cloudu.
- Google Cloud Composer (cloud.google.com/composer/)
- Služba pro orchestraci toku práce v Google Cloudu. Je založen na Apache Airflow a umožňuje vytváření, plánování a monitorování složitých toků práce v cloudu.
- Prefect (prefect.io)
- Open-source nástroj pro orchestraci toku práce a správu úloh v Pythonu. Poskytuje flexibilitu při vytváření a plánování toků práce a podporuje spolupráci mezi týmy.
- Luigi (github.com/spotify/luigi)
- Open-source framework pro tvorbu složitých toků práce v Pythonu. Je vyvinutý společností Spotify a umožňuje definovat a spouštět tok práce pomocí Python kódu.
- Flyte (flyte.org)
- Platforma pro orchestraci toku práce a správu úloh vyvinutá společností Lyft. Je navržena tak, aby umožňovala snadné vytváření, spouštění a monitorování distribuovaných toků práce.
Ještě chci zmínit poslední nástroj, který neumožňuje orchestraci, ale umožnuje kreslit schémata. A tím například popsat toky v orchestraci nebo jiné zajímavé věci. Tento nástroj je yEd (yworks.com/products/yed). Pomocí něj také kreslím doplňující „žluté“ obrázky k článkům.
Shrnutí
Orchestrace slouží ke správě a plánování spouštění přenosů dat do/uvnitř/z DWH.
Load probíhá v noci nebo brzo ráno – časově náročná operace.
Nejdříve se loadují data do l0 a následně se zpracovávají vrstvy datového skladu.
Je možné určité části loadu paralelizovat.
Existuje velké množství nástrojů, které lze pro orchestraci použít.
Doporučené články
Předchozí články
Co je to datový sklad (DWH)? – 1. díl
Základní tipy v datovém skladu (DWH) – 2. díl
Vrstvy datového skladu (DWH) – 3. díl
Pojmenovávání a dokumentace – 8. díl
Následující
Pokročilé agregační funkce – 10. díl
Příklady
Nastavení DWH v PostgreSQL – 1.příklady
SELECT dotazování – 2. příklady