Optimalizace je velmi důležité téma a optimalizace v datovém skladu může být občas trochu odlišná od optimalizace v OLTP systémech. Důležité je zmínit exekuční plán, statistiky, způsoby joinování, materializaci, indexy a partitioning. Toto je jedna z náročnějších kapitol na čtení a je poměrně obsáhlá – hodí se mít vhled do teorie grafů. Exekuční plán Když vytvořím databázový dotaz. Existuje k němu několik exekučních plánů. Databáze je vytvoří na pozadí a vybere z nich ten, o kterém si myslí, že je nejlepší (A né vždy si to myslí správně a je jí potřeba popostrčením navést ke správnému řešení). Každý plán má určitou cenu, kterou databáze vypočte na základě statistik, které si…
-
-
Pokročilé agregační funkce – 10. díl
V nadcházejícím článku se zaměřím na windowed funkce. Ty provádějí pokročilé agregace nad specifickým "oknem" řádků, což rozšiřuje možnosti analýz. Věnuji si funkcím ROW_NUMBER, RANK, LEAD, LAG, FIRST_VALUE a dalším. Ukážu konkrétní příklady využití.
-
Pojmenovávání a dokumentace – 8. díl
Půjde o pojmenovávání a dokumentaci. Je extrémně důležité vést k celému projektu dokumentaci, správně pojmenovávat a dobře komunikovat. Ne vždy se tato aktivita setkává s pochopením, ale je nesmírně důležitá. Lidé si na to časem zvyknou a ve finále je daleko lepší provoz, někdy dokonce i levnější. Jak už komentovat kód, tak stejným stylem pojmenovávat objekty, používat jednotný code style. Uvedu tu několik dobrých principů, kterých se držet, aby Vám práce šla lépe.
-
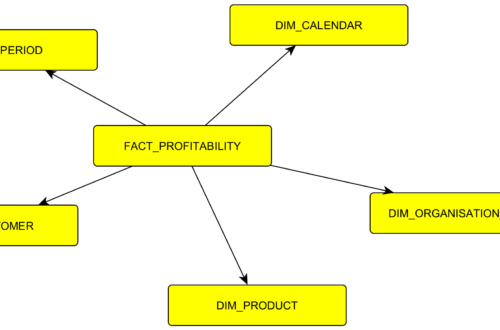
Fakta v datovém skladu (DWH) – 7. díl
V tomto článku se věnuji faktovým tabulkám. Ukážu příklad na fakturách, dále se věnuji propojení faktových tabulek s dimenzemi, zmíním se o periodě loadu. K článku přikládám v odkazech i link na příklady v SQL, které si můžete při čtení zkoušet.
-
Dimenze v datovém skladu (DWH) – 6. díl
V tomto článku se podívám podrobněji na dimenze, jejich typy - STAR/SNOWFLAKE/CONSTELLATION, jejich plnění, úrovně historizace a typické dimenze v datovém skladu.
-
SQL funkce a DML – 5. díl
Rychle prolétnu zajímavé funkce, příkazy z SQL a zbylé DML operace INSERT, UPDATE, DELETE a MERGE. Pokud se na to cítíte můžete určitě článek přeskočit. V příštím už se konečně dostaneme k věcem bližším DWH.
-
SELECT – 4. díl
Tentokrát se věnuji klauzuli SELECT, a jejím příkazům, podrobněji se podívám na JOINy a jejich typy. Jelikož SELECT a JOINy jsou pro DWH stěžějní je potřeba se u nich pozastavit.
-
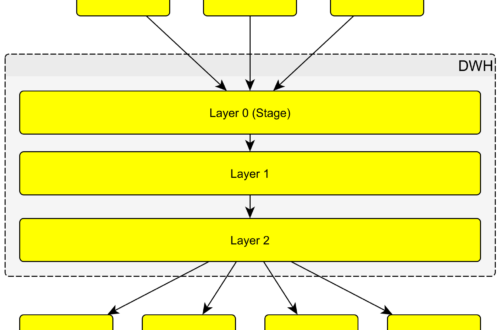
3 vrstvy datového skladu (DWH) – 3. díl
Zde se podrobněji věnuji vrstvám datového skladu. Jejich rozdělení, použití, externím tabulkám, výpočtům, přenosem mezi vrstvami, a také dimenzím a faktům. K článku přikládám jednoduchý soubor s příklady pro vytvoření databáze v PostgreSQL a schémat jako jednotlivých vrstev. DWH je rozdělen na vrstvy. Vrstvy l0, l1, l2 v DWH je jen označení, aby bylo zřejmé v jakém směru data plynou (l0 -> l1 -> l2). Samotné vrstvy pak reprezentuje schéma databáze. Když navrhuji tabulky v DWH, musím myslet na to, že pracuji s historickými daty. Kdykoliv udělám v průběhu vývoje změnu je třeba přepočíst všechny vrstvy, co se změnou souvisí i za všechna časová období. Jednodušeji řečeno – je možné celou tabulku smazat (platí pro…
-
Základní tipy v datovém skladu (DWH) – 2. díl
V tomto článku se podívám na dobré návyky v datovém skladu a základní tipy co Vám zlepší život, co se týče datových typů, transakčních dat vs. master dat a datumů.
-
Co je to datový sklad (DWH)? – 1. díl
Tento článek i následující články píši na témata o DWH (= DataWareHouse), BI (= Business Intelligence) a SQL (= Structured Query Language). Věnuji se datovému skladu, jeho vrstvám a rozdílu oproti relační databázi. Na internetu lze najít různé materiály o klasických relačních databázích, ale chyběl mi nějaký ucelený návod o datovém skladu, a proto jsem ho vytvořil. Než se do čtení pustíte, je dobré znát co je to relační databáze a SQL.