Zde se podrobněji věnuji vrstvám datového skladu. Jejich rozdělení, použití, externím tabulkám, výpočtům, přenosem mezi vrstvami, a také dimenzím a faktům. K článku přikládám jednoduchý soubor s příklady pro vytvoření databáze v PostgreSQL a schémat jako jednotlivých vrstev.
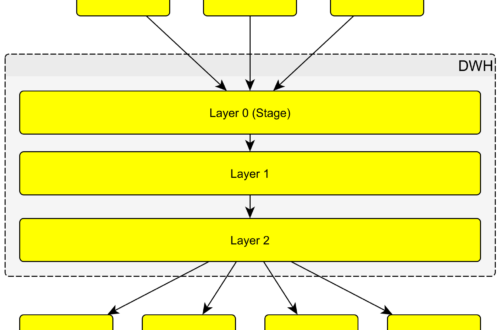
DWH je rozdělen na vrstvy. Vrstvy l0, l1, l2 v DWH je jen označení, aby bylo zřejmé v jakém směru data plynou (l0 -> l1 -> l2). Samotné vrstvy pak reprezentuje schéma databáze.
Když navrhuji tabulky v DWH, musím myslet na to, že pracuji s historickými daty. Kdykoliv udělám v průběhu vývoje změnu je třeba přepočíst všechny vrstvy, co se změnou souvisí i za všechna časová období. Jednodušeji řečeno – je možné celou tabulku smazat (platí pro l1 vrstvu a dál) a pak ji přepočíst od počátku věků z l0 vrstvy a dostanu se ke stejným datům jako jsem měl předtím s obohacením o provedenou změnu. Vše je opakovatelně spustitelné.

Vrstva l0 (Stage)
Vrstva l0 je 1:1 datová struktura ze zdrojového systému. Jelikož je zdrojových systémů více, tak mám i několik schémat l0. Například l0_crm, l0_erp, l0_ext, l0_weather, … Postfix by měl jasně identifikovat zdrojový systém. Prefix „l“ jsem zvolil, jen aby to vypadalo hezky, a „l“ jako layer – jakákoliv pojmenování jsou pouze moje doporučení, pojmenujte vrstvy jak uznáte za vhodné, třeba lama0, lama1, lama2.
Externí tabulky
Zmínil jsem l0_ext. Schéma reprezentuje externí tabulky. To jsou tabulky, které nevstupují do DWH ze žádného systému, ale upravuje je nějaký člověk ručně. Buď přímo pomocí SQL nebo jiným způsobem. Typicky se jedná o číselníky a podobné věci, kteří si lidé ve firmě ‚pytlíkují‘ někde v excelu u sebe, ale chtěli by s tím propojovat data v DWH. Takže se musí nakonec přesunout do DWH a musí se tam i udržovat. Nejlepší by bylo se externím tabulkám úplně vyhnout, ale je to téměř nemožné. A protože každá externí tabulka je potenciální problém, je potřeba o každé udržovat základní dokumentaci – k čemu je, jaká data se tam nahrávají, kdo je za ní zodpovědný.
Přenos dat do/v DWH
Existují 2 magická slůvka ETL (= Extract Transform Load) a ELT (= Extract Load Transform). Ano jak jste odhadli jde pouze o to v jakém pořadí se dané operace provedou. Existují aplikace, které umí tyto přenosy dat zprostředkovat (Pentaho, Keboola, …). Na vstupu jim řeknu odkud data tahám. Může to být CSV, JSON, XML, TXT, excel uložený na FTP, jiná databáze atd. Dál jim řeknu jestli se mají data transformovat a kam se mají uložit (DWH). Typicky používám ETL – data transformuji, jelikož nesedí například datové typy apod.
Nejlepší způsob je, pokud mám k DWH přímo nalinkovaný server s databázi aplikace (může být vnímáno jako security issue). A data stáhnu velmi elegantním loadem:
TRUNCATE TABLE DWH.L0_APPLICATION1.TABLE_NAME; INSERT INTO DWH.L0_APPLICATION1.TABLE_NAME (COLUMN1, COLUMN2, …) SELECT COLUMN1, COLUMN2, … FROM APPLICATION1_DATABASE.SCHEMA.TABLE_NAME;
Co se týče přenosu uvnitř DWH stačí použít kombinaci DELETE-INSERT-SELECT jako výše. Vytvořím SELECT, před kterým je INSERT INTO a také potřebuji DELETE/TRUNCATE, který před INSERTem tabulku promaže – typicky nemažu všechna data v tabulce, ale jen data za určité období – přírůstky (tady se velmi hodí identifikátor období). Pokud používáte framework pro generování kódu, tuto část Vám také velmi usnadní, neboť pattern je neustále stejný, jediné co se mění je SELECT část a cílová tabulka.
Vrstva l1
Vrstva l1 vychází z vrstvy l0 a už pracuje s jejími daty. V přenosu do l1 je vhodné odstranit úvodní nuly, přidat identifikátory období, dělat výpočty a přidat pomocné pole pro výpočty, které budou následovat – záleží na konkrétním problému. A potom je vhodné do l1 vrstvy nepřenášet sloupce, které momentálně nepotřebuji – dají se kdykoliv přidat.
Bude třeba hodně výpočtů. Například co se týče profitability. V té je typicky hned několik metrik jako náklady, obrat, DPH, spotřební daň, slevy, profit, atd. Všechny tyto metriky musím vypočítat. A tento výpočet by se měl dít na úrovni l1 a l2 vrstev. V l1 už je dobré vypočítat různé metriky a pak je propagovat dále do l2 vrstvy a z nich počítat další metriky (pro výpočet profitu potřebuji velkou většinu z předchozích metrik).
Uváděl jsem metriky finanční (v každé firmě), ale kromě nich existují i další, které už se typicky odvíjejí od konkrétního businessu. Například hmotnost, objem, kusy…. Je dobré poznamenat, že profitabilita je komplexní a poměrně složitá záležitost, hlavně díky vysokému množství vstupů. Existují, ale i jiné věci co budete chtít sledovat kromě profitability.
Ještě chci poznamenat, že bod výpočtů je nejvíce důležitý oproti předchozím bodům, které jsem k l1 vrstvě popisoval – ostatní jsou převážně vylepšení, které zlepší práci, ale nejsou tak důležité jako výpočty, které jsou použité pro analýzy – primární účel DWH.
Vrstva l2
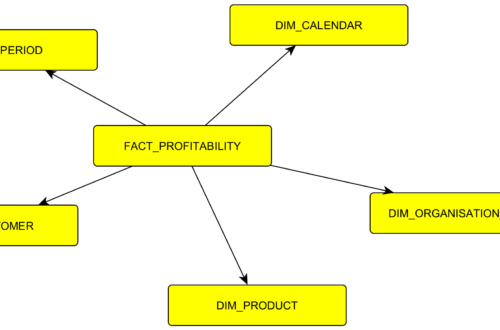
Vrstva l2 je primárně o výpočtech a je to část, do které mají přístup uživatelé k dotazování. Skládá se převážně z dimenzí a faktových tabulek. Tabulka s fakty obsahuje číselné hodnoty a cizí klíče do dimenzí. Dimenzi si představte jako číselník (enum). Typicky jsou v DWH dimenze zákazníka, produktu, kalendáře, organizační struktura a další. Nejlepší pro představu je příklad. Dejme tomu, že mám faktovou tabulku. V té jsou informace z faktury, tedy číselné hodnoty: # kusů, cena bez DPH. Dále obsahuje cizí klíče, datum, číslo faktury, id produktu, id zákazníka. A pak mám dimenze.
DIM_CALENDAR
Primární klíč je datum, další informace: pracovní den, den v týdnu, … stačí vypočítat jednou (data v tabulce se neměnní). Samotné naplnění tabulky je velmi zajímavé, neboť lze využít techniku rekurze v SQL.
| Sloupec | Typ | Vlastnosti | Popis |
| DIM_CALENDAR_DATE | DATE | PRIMARY KEY | Den ‚2023-12-31‘ |
| WEEK_DAY | SMALLINT | NOT NULL | Den v týdnu. Neděle = 0, pondělí= 1, …, sobota = 6 |
| WEEK_DAY_DESCR | VARCHAR(50) | NOT NULL | Texty ke dnu v týdnu: Sunday, Monday, …, Saturday |
| WEEK_DAY_DESCR_SHORT | VARCHAR(10) | NOT NULL | Krátké texty ke dnu v týdnu: Sun, Mon, …, Sat |
| WEEK_NUMBER | SMALLINT | NOT NULL | Číslo týdne v roce |
| QUARTER_ID | VARCHAR(10) | NOT NULL | Kvartál ve formátu ‚Q4 2023‘ |
| FLAG_WORKING_DAY | SMALLINT | NOT NULL | Flag 1/0 -> 1 = pracovní den (není víkend, není svátek) |
| FLAG_WEEKEND | SMALLINT | NOT NULL | Flag 1/0 -> 1 = víkend (sobota nebo neděle) |
| FLAG_HOLIDAY | SMALLINT | NOT NULL | Flag 1/0 -> 1 = svátek |
DIM_CUSTOMER
Obsahuje informace o zákaznících, fakturační údaje, různé businessová dělení do kategorií – mohou to být hierarchické struktury (například dělení domestic/export, které se dále rozpadá v domestic na velkoobchod, maloobchod, e-commerce atd.), přiřazený obchodní zástupce, jestli je zákazník aktivní a spousty dalších informací.
V dimenzi nemusí být hodnoty přímo, ale jako cizí klíče s odkazem do jiné dimenze – typicky segmentace zákazníka je číselník (například s kódem 01 a hodnotou Domestic, 02 a hodnotou Export) ze zdrojové aplikace a samotný číselník může být v jiné dimenzi. Ovšem u často používaných atributů doporučuji hodnoty dotáhnout přímo do dimenze zákazníka (denormalizace), bude tam jak kód tak hodnota (vzniká redundance dat – ale urychlí to SELECT následně o JOIN).
| Sloupec | Typ | Vlastnosti | Popis |
| DIM_CUSTOMER_ID | VARCHAR(255) | PRIMARY KEY | Id zákazníka ‚55455‘ |
| CUSTOMER_NAME | VARCHAR(255) | NOT NULL | Jméno zákazníka |
| CUSTOMER_ADDRESS | VARCHAR(255) | NOT NULL | Adresa zákazníka |
| CUSTOMER_PHONE | VARCHAR(50) | Telefonní číslo | |
| CUSTOMER_SEGMENTATION_01_ID | SMALLINT | NOT NULL | Zákaznická top (lvl1) segmentace – kód, 1 = Domestic, 2 = Export |
| CUSTOMER_SEGMENTATION_01_TEXT | VARCHAR(10) | NOT NULL | Zákaznická top (lvl1) segmentace – text, 1 = Domestic, 2 = Export |
| CUSTOMER_SEGMENTATION_02_ID | SMALLINT | NOT NULL | Zákaznická lvl2 segmentace kód |
| CUSTOMER_SEGMENTATION_02_TEXT | VARCHAR(10) | NOT NULL | Zákaznická lvl2 segmentace text |
| … | … | … | … |
Další dimenze
Další dimenze vypadají obdobně například DIM_PERIOD (v podstatě agregace kalendáře na úroveň měsíce nebo jiné vhodné časové periody), DIM_PRODUCT, DIM_ORGANISATION_STRUCUTRE, … Tento systém s dimenzemi a faktovými tabulkami je výhodný pro dotazování. Říká se tomu také STAR/SNOWFLAKE až po CONSTELLATION schéma. Také se lze potkat s termínem data mart -konkrétní podmnožina dimenzí a faktů pro konkrétní problém.
Oficiálně STAR znamená 1 faktová tabulka a dimenze s redundantním uložením, které jsem popsal výše. SNOWFLAKE je stejný, jen s joinem navíc (bez redundance). Ve výsledku stejně používám kombinaci STAR/SNOWFLAKE podle toho jak často s daty pracuji, kde si ten JOIN navíc můžu dovolit a kde ne. No a CONSTELLATION znamená, že máte několik STAR/SNOWFLAKE – mám více faktových tabulek. Termíny se hodí na googlení, ve výsledku používáte dle potřeby. Na obrázku je vidět jak to může vypadat.
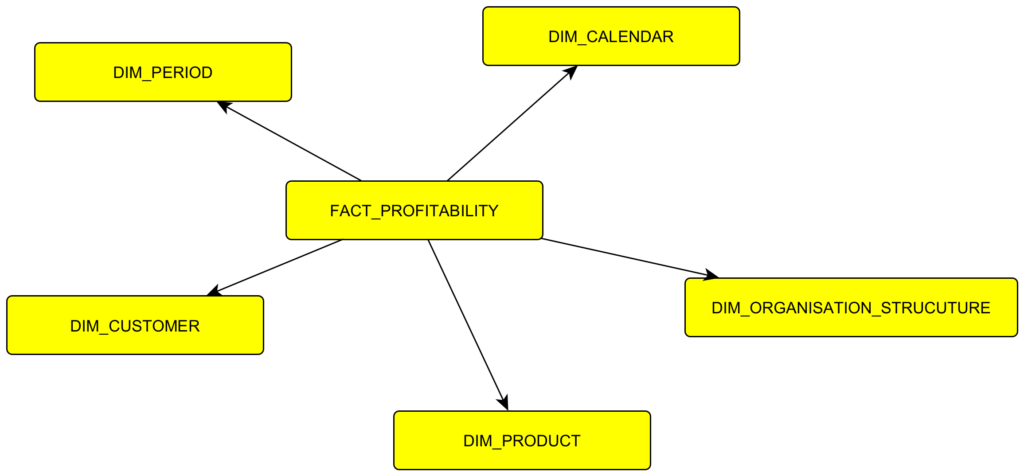
Následný SELECT pak vypadá přibližně takto:
SELECT src.DIM_PERIOD_DATE, cust.CUSTOMER_SEGMENTATION_01_TEXT, pro.PRODUCT_FAMILY, pro.PRODUCT_NAME, sum(src.QUANTITY) AS QUANTITY, sum(src.PRICE_WITHOUT_VAT) AS PRICE_WITHOUT_VAT FROM l2.FACT_PROFITABILITY src JOIN l2.DIM_CUSTOMER cust ON cust.DIM_CUSTOMER_ID = src.DIM_CUSTOMER_ID JOIN l2.DIM_PRODUCT pro ON pro.DIM_PRODUCT_ID = src.DIM_PRODUCT_ID WHERE src.DIM_PERIOD_DATE BETWEEN '2023-01-01' AND '2023-12-31' GROUP BY src.DIM_PERIOD_DATE, cust.CUSTOMER_SEGMENTATION_01_TEXT, pro.PRODUCT_FAMILY, pro.PRODUCT_NAME
Shrnutí
- Vrstva l0 slouží jako přistávací plocha dat z různých zdrojových systémů. Všechny přepočty za l0 dál jsou znovu spustitelné.
- Externím tabulkách se chci vyhnout – bohužel to ale nejde. Je potřeba k nim vést dokumentaci a udržovat je ručně.
- Přenost dat do l0 se provádí pomocí ETL nástrojů. Přenos uvnitř DWH dělám pomocí DELETE-INSERT-SELECT, případně merge/update.
- V l1 vrstvě si připravuji data do zpracovatelnější podoby a začínám s výpočty.
- Klíčový prvek v nejvyšší vrstvě l2 jsou dimenze a fakta, uspořádané do STAR/SNOWFLAKE/CONSTELLATION systému. Fakta jsou číselné hodnoty, které se dají agregovat. Dimenze mají statické atributy.
Doporučené články
Předchozí články
Co je to datový sklad (DWH)? – 1. díl
Základní tipy v datovém skladu (DWH) – 2. díl
Následující články
Příklady
Nastavení DWH v PostgreSQL (TXT soubor s příklady) Examples.DWH
SELECT dotazování – 2. příklady
User-defined funkce – 3. příklady